Context and Problem Statement🔗
How can office documents, like docx or odt be converted into a PDF
file that looks as much as possible like the original?
It would be nice to have a java-only solution. But if an external tool has a better outcome, then an external tool is fine, too.
Since Docspell is free software, the tools must also be free.
Considered Options🔗
- Apache POI together with this library
- pandoc external command
- abiword external command
- Unoconv external command
To choose an option, some documents are converted to pdf and compared.
Only the formats docx and odt are considered here. These are the
most used formats. They have to look well, if a xlsx or pptx
doesn't look so great, that is ok.
Here is the native view to compare with:
ODT:

XWPFConverter🔗
I couldn't get any example to work. There were exceptions:
java.lang.IllegalArgumentException: Value for parameter 'id' was out of bounds
at org.apache.poi.util.IdentifierManager.reserve(IdentifierManager.java:80)
at org.apache.poi.xwpf.usermodel.XWPFRun.<init>(XWPFRun.java:101)
at org.apache.poi.xwpf.usermodel.XWPFRun.<init>(XWPFRun.java:146)
at org.apache.poi.xwpf.usermodel.XWPFParagraph.buildRunsInOrderFromXml(XWPFParagraph.java:135)
at org.apache.poi.xwpf.usermodel.XWPFParagraph.<init>(XWPFParagraph.java:88)
at org.apache.poi.xwpf.usermodel.XWPFDocument.onDocumentRead(XWPFDocument.java:147)
at org.apache.poi.POIXMLDocument.load(POIXMLDocument.java:159)
at org.apache.poi.xwpf.usermodel.XWPFDocument.<init>(XWPFDocument.java:124)
at docspell.convert.Testing$.withPoi(Testing.scala:17)
at docspell.convert.Testing$.$anonfun$run$1(Testing.scala:12)
at cats.effect.internals.IORunLoop$.cats$effect$internals$IORunLoop$$loop(IORunLoop.scala:87)
at cats.effect.internals.IORunLoop$RestartCallback.signal(IORunLoop.scala:355)
at cats.effect.internals.IORunLoop$RestartCallback.apply(IORunLoop.scala:376)
at cats.effect.internals.IORunLoop$RestartCallback.apply(IORunLoop.scala:316)
at cats.effect.internals.IOShift$Tick.run(IOShift.scala:36)
at cats.effect.internals.PoolUtils$$anon$2$$anon$3.run(PoolUtils.scala:51)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
The project (not Apache Poi, the other) seems unmaintained. I could not find any website and the artifact in maven central is from 2016.
Pandoc🔗
I know pandoc as a very great tool when converting between markup
documents. So this tries it with office documents. It supports docx
and odt from there --list-input-formats.
From the pandoc manual:
By default, pandoc will use LaTeX to create the PDF, which requires that a LaTeX engine be installed (see --pdf-engine below). Alternatively, pandoc can use ConTeXt, roff ms, or HTML as an intermediate format. To do this, specify an output file with a .pdf extension, as before, but add the --pdf-engine option or -t context, -t html, or -t ms to the command line. The tool used to generate the PDF from the intermediate format may be specified using --pdf-engine.
Trying with latex engine:
pandoc -f odt -o test.pdf example.odt
Results ODT:

pandoc -f odt -o test.pdf example.docx
Results DOCX:

Trying with context engine:
pandoc -f odt -t context -o test.pdf example.odt
Results ODT:

Results DOCX:

Trying with ms engine:
pandoc -f odt -t ms -o test.pdf example.odt
Results ODT:

Results DOCX:

Trying with html engine (this requires wkhtmltopdf to be present):
$ pandoc --extract-media . -f odt -t html -o test.pdf example.odt
Results ODT:

Results DOCX:

Abiword🔗
Trying with:
abiword --to=pdf example.odt
Results:

Trying with a docx file failed. It worked with a doc file.
Unoconv🔗
Unoconv relies on libreoffice/openoffice, so installing it will result in installing parts of libreoffice, which is a very large dependency.
Trying with:
unoconv -f pdf example.odt
Results ODT:

Results DOCX:
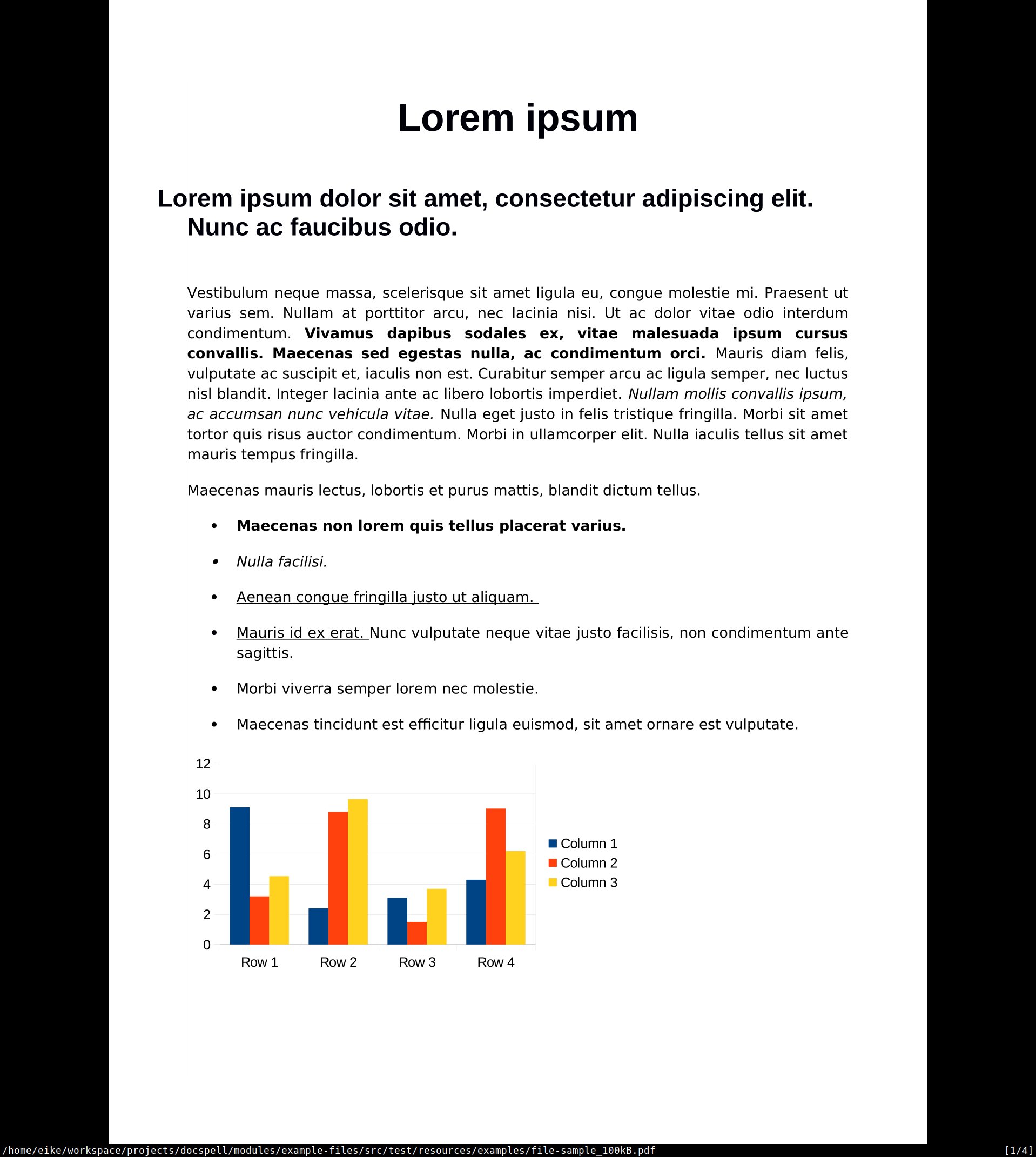
Decision Outcome🔗
Unoconv.
The results from unoconv are really good.
Abiword also is not that bad, it didn't convert the chart, but all font markup is there. It would be great to not depend on something as big as libreoffice, but the results are so much better.
Also pandoc deals very well with DOCX files (using the context
engine). The only thing that was not rendered was the embedded chart
(like abiword). But all images and font styling was present.
It will be a configurable external command anyways, so users can exchange it at any time with a different one.