Scan Mailboxes🔗
User that provide valid email (imap) settings, can import mails from their mailbox into docspell periodically.
You need first define imap settings, please see this page.
Go to User Settings -> Scan Mailbox Task. You can define periodic tasks that connects to your mailbox and import mails into docspell. It is possible to define multiple tasks, for example, if you have multiple e-mail accounts you want to import periodically.
Details🔗
General🔗
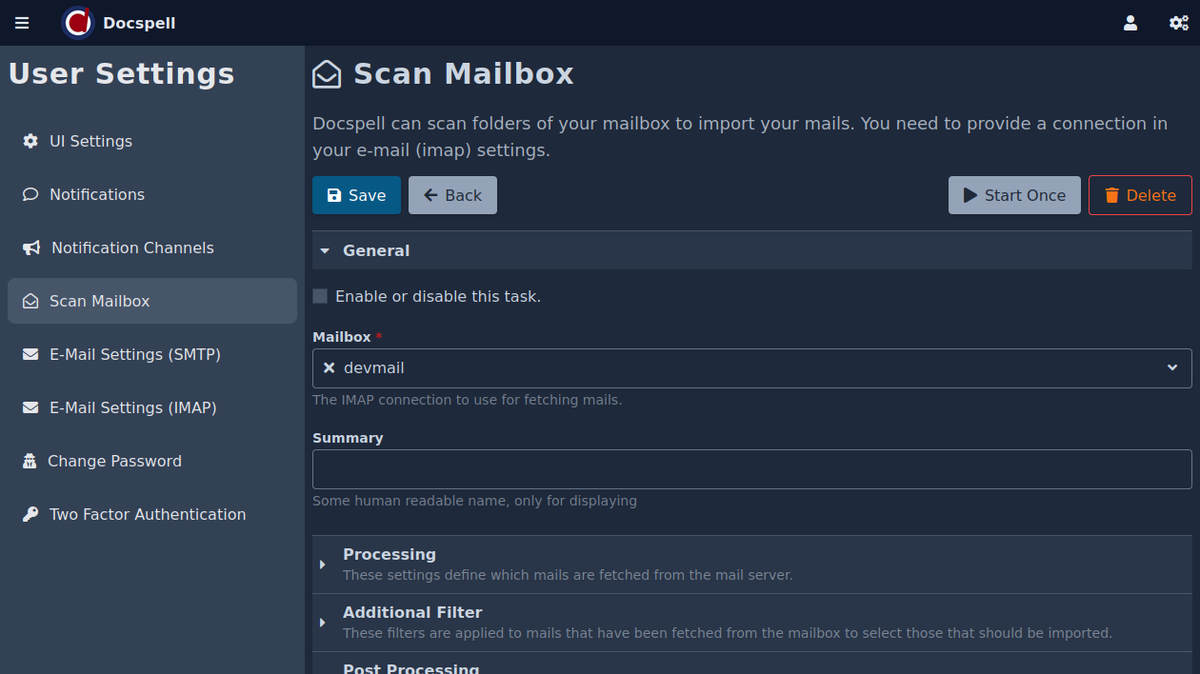
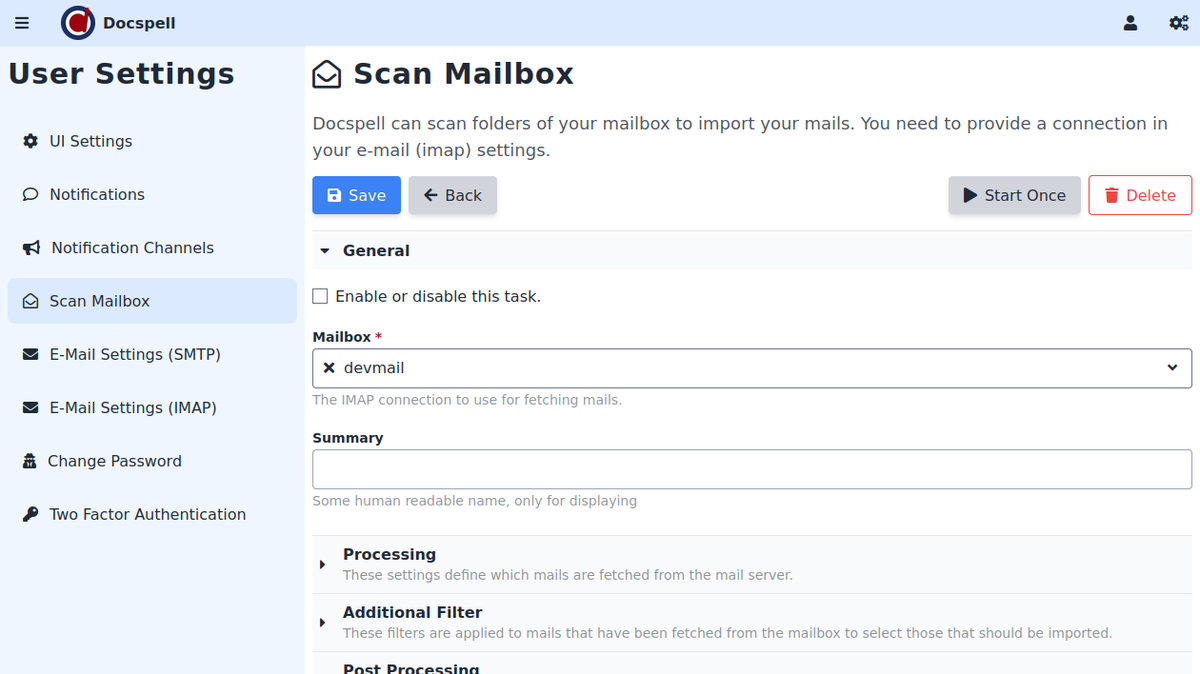
You can enable or disable this task. A disabled task will not run
periodically. You can still choose to run it manually if you click the
Start Once button.
Then you need to specify which IMAP connection to use.
Processing🔗
A list of folders is required. Docspell will only look into these folders. You can specify multiple folders. The "Inbox" folder is a special folder, which will usually appear translated in your web-mail client. You can specify "INBOX" case insensitive, it will then read mails in your inbox. Any other folder is usually case-sensitive (depends on the imap server, but usually they are case sensitive except the INBOX folder). The path separator may also vary depending on your imap server - if the slash doesn't work, try using a dot (i.e. "INBOX.invoices" instead of "INBOX/invoices"). Type in a folder name and click the add button on the right.
Then the field Received Since Hours defines how many hours to go back and look for mails. Usually there are many mails in your inbox and importing them all at once is not feasible or desirable. It can work together with the Schedule field below. For example, you could run this task all 6 hours and read mails from 8 hours back. This setting is used to query the mail server.
Additional Filter🔗
The following properties allow to filter those downloaded mails that should be imported.
The File Filter can be specified as a glob to only import mail
attachments based on their file name. For example, a value of *.pdf
will only import files that have a pdf extension. The mail body is
named mail.html by convention and would be excluded when only
specifying *.pdf. You can combine multiple globs using OR via the
pipe | symbol. For example, to also include the mail body as well as
all pdf attachments: *.pdf|mail.html.
The Subject Filter is a glob filter that is applied to the mail
subject. This can be used to only import mails whose subject have some
pattern. For example, if your scanner mails to you with a certain
subject like "Scanned Document 214", you could include those via a
Scanned Document* pattern.
Post Processing🔗
The next settings tell docspell what to do once a mail has been read by docspell. It can be moved into another folder in your mail account. This moves it out of the way for the next run. You can also choose to delete the mail, but note that it will really be deleted and not moved to your trash folder. If both options are off, nothing happens with that mail, it simply stays (and could be re-read on the next run).
Be careful when mails are neither moved nor deleted after processing.
They could be selected anew in the next run, meaning that the job can
not progress, because it filters out the same mails all the time. You
can however, simply schedule the task in an interval >= the Received Since Hours setting.
By default, post-processing is only applied to mails that have been submitted to docspell. Some mails may have been skipped due subject filtering. If you also want these skipped mails to be affected by post-processing, enabled the Apply post-processing to all fetched mails.
Metadata🔗
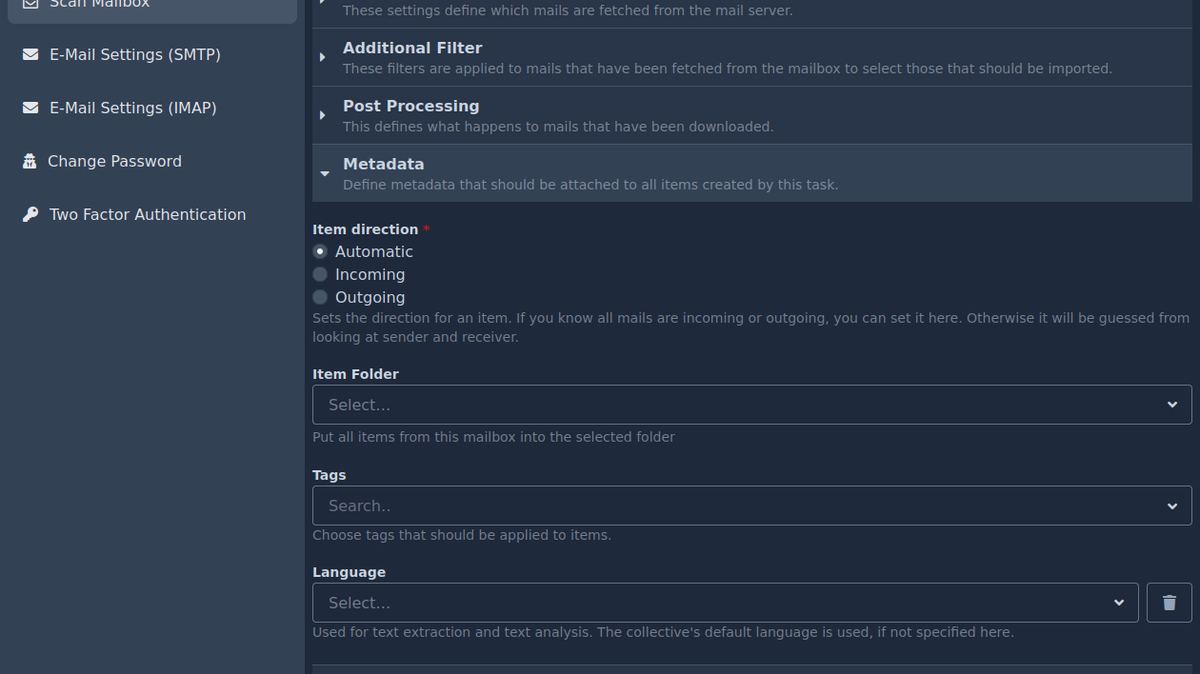
These properties allow to specify some metadata that are automatically attached to the items being created.
Every item in docspell has a direction value (incoming or outgoing).
If you know that all mails you want to import have a specific
directon, then you can set it here. Otherwise, automatic means that
docspell chooses a direction based on the From header of a mail. If
the From header is an e-mail address that belongs to a “concerning”
person in your address book, then it is set to "outgoing". Otherwise
it is set to "incoming". To support this, you need to add your own
e-mail address(es) to your address book.
The Item Folder setting is used to put all items that are created from mails into the specified folder. If you define a folder here, where you are not a member, you won't find resulting items.
The Tags setting can be used to associate a fixed number of tags to all items that are imported from this mail task.
The Language setting is applied when processing the mails. If not set, the default language of the collective is used.
Schedule🔗
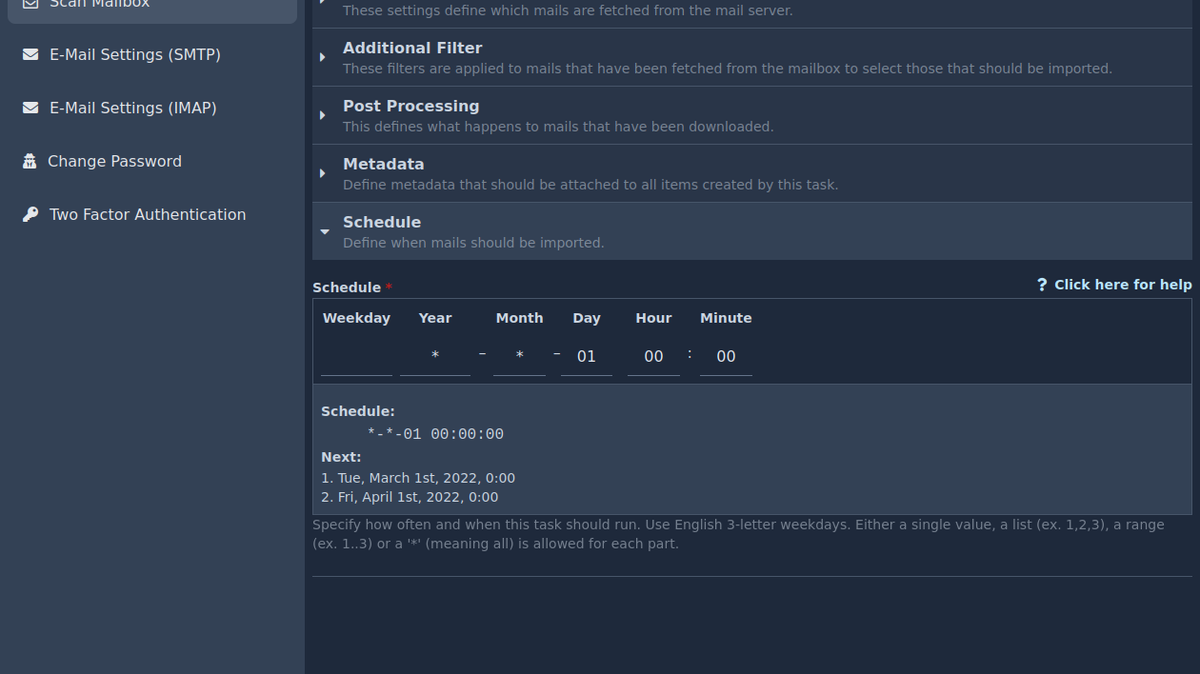
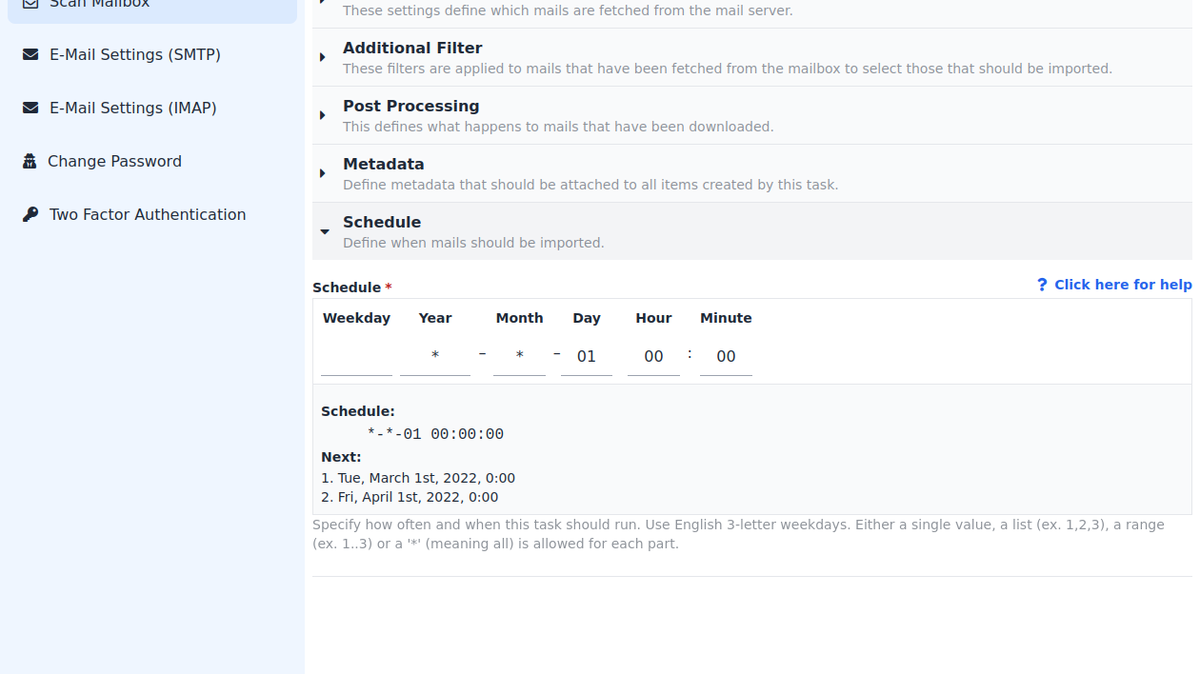
At last the Schedule defines when and how often this task should
run. The syntax is similiar to a date-time string, like 2019-09-15 12:32, where each part is a pattern to also match multple values. The
ui tries to help a little by displaying the next two date-times this
task would execute. A more in depth help is available
here.
For example, to execute the task every monday at noon, you would
write: Mon *-*-* 12:00. A date-time part can match all values (*),
a list of values (e.g. 1,5,12,19) or a range (e.g. 1..9). Long
lists may be written in a shorter way using a repetition value. It is
written like this: 1/7 which is the same as a list with 1 and all
multiples of 7 added to it. In other words, it matches 1, 1+7,
1+7+7, 1+7+7+7 and so on.
Configuraion🔗
The admin can tweak some properties in the config file at
docspell.joex.user-tasks.scan-mailbox:
max-folders: Maximum number of folders to scan. This sets a hard limit on the folder selection of the user settings.mail-chunk-size: the batch size to use when fetching mails; after this many mails have been processed, the connection is re-established to get the nextmail-chunk-sizemails.max-mails: the maximum amount of mails to process in one job run. If the mailbox contains more than this amount of mails, it must be waited for the next scheduled executon.
Reading Mails twice / Duplicates🔗
Since users can move around mails in their mailboxes, it can happen that docspell unintentionally reads a mail multiple times. If docspell reads a mail, it will first check if an item already exists that originated from this mail. It only proceeds to import it, if it cannot find any. If you deleted an item in the meantime, docspell would import the mail again.
This check uses the
Message-ID of an e-mail.
This is usually there and should identify a complete mail. But it
won't catch duplicate mails, that are sent multiple times - they might
have different Message-IDs. Also some mails have no such ids and are
then imported from docspell without any checks.
In later versions, docspell may use the checksum of the generated eml file to look for duplicates, too.
How it works🔗
Docspell will go through all folders and download mails in “batches”. This size can be set by the admin in the configuration file and applies to all these tasks (same for all users). This batch only contains the mail headers and not the complete mail.
Then each mail is downloaded completely one by one and converted into an eml file which is then submitted to docspell. Then the usual processing machinery starts, just like uploading an eml file via the webapp.
The number of folders and the number of mails to import can be limited by an admin via the config file. Note that this limit applies to one task run only, it is meant to reduce resource allocation of one task.