Context and Problem Statement🔗
Docspell currently only supports PDF files. This has simplified early development and design a lot and so helped with starting the project. Handling pdf files is usually easy (to view, to extract text, print etc).
The pdf format has been chosen, because PDFs files are very common and can be viewed with many tools on many systems (i.e. non-proprietary tools). Docspell also is a document archive and from this perspective, it is important that documents can be viewed in 10 years and more. The hope is, that the PDF format is best suited for this. Therefore all documents in Docspell must be accessible as PDF. The trivial solution to this requirement is to only allow PDF files.
Support for more document types, must then take care of the following:
- extracting text
- converting into pdf
- access original file
Text should be extracted from the source file, in case conversion is not lossless. Since Docspell can already extract text from PDF files using OCR, text can also be extracted from the converted file as a fallback.
The original file must always be accessible. The main reason is that all uploaded data should be accessible without any modification. And since the conversion may not always create best results, the original file should be kept.
Decision Drivers🔗
People expect that software like Docspell support the most common
document types, like all the “office documents” (docx, rtf, odt,
xlsx, …) and images. For many people it is more common to create
those files instead of PDF. Some (older) scanners may not be able to
scan into PDF files but only to image files.
Considered Options🔗
This ADR does not evaluate different options. It rather documents why this feature is realized and the thoughts that lead to how it is implemented.
Realization🔗
Data Model🔗
The attachment table holds one file. There will be another table
attachment_source that holds the original file. It looks like this:
(
"id" varchar(254) not null primary key,
"file_id" varchar(254) not null,
"filename" varchar(254),
"created" timestamp not null,
foreign key ("file_id") references "filemeta"("id"),
foreign key ("id") references "attachment"("attachid")
);
The id is the primary key and is the same as the associated
attachment, creating a 1-1 relationship (well, more correct is
0..1-1) between attachment and attachment_source.
There will always be a attachment_source record for every
attachment record. If the original file is a PDF already, then both
table's file_id columns point to the same file. But now the user can
change the filename of an attachment while the original filename is
preserved in attachment_source. It must not be possible for the user
to change anything in attachment_source.
The attachment table is not touched in order to keep current code
mostly unchanged and to have a simpler data migration. The downside
is, that the data model allows to have an attachment record without
an attachment_source record. OTOH, a foreign key inside attachment
pointing to an attachment_source is also not correct, because it
allows the same attachment_source record to be associated with many
attachment records. This would do even more harm, in my opinion.
Migration🔗
Creating a new table and not altering existing ones, should simplify data migration.
Since only PDF files where allowed and the user could not change
anything in the attachment table, the existing data can simply be
inserted into the new table. This presents the trivial case where the
attachment and source are the same.
Processing🔗
The first step in processing is now converting the file into a pdf. If it already is a pdf, nothing is done. This step is before text extraction, so text can first be tried to extract from the source file and only if that fails (or is not supported), text can be extracted from the converted pdf file. All remaining steps are untouched.
If conversion is not supported for the input file, it is skipped. If conversion fails, the error is propagated to let the retry mechanism take care.
What types?🔗
Which file types should be supported? At a first step, all major
office documents, common images, plain text (i.e. markdown) and html
should be supported. In terms of file extensions: doc, docx,
xls, xlsx, odt, md, html, txt, jpg, png, tif.
There is always the preference to use jvm internal libraries in order to be more platform independent and to reduce external dependencies. But this is not always possible (like doing OCR).
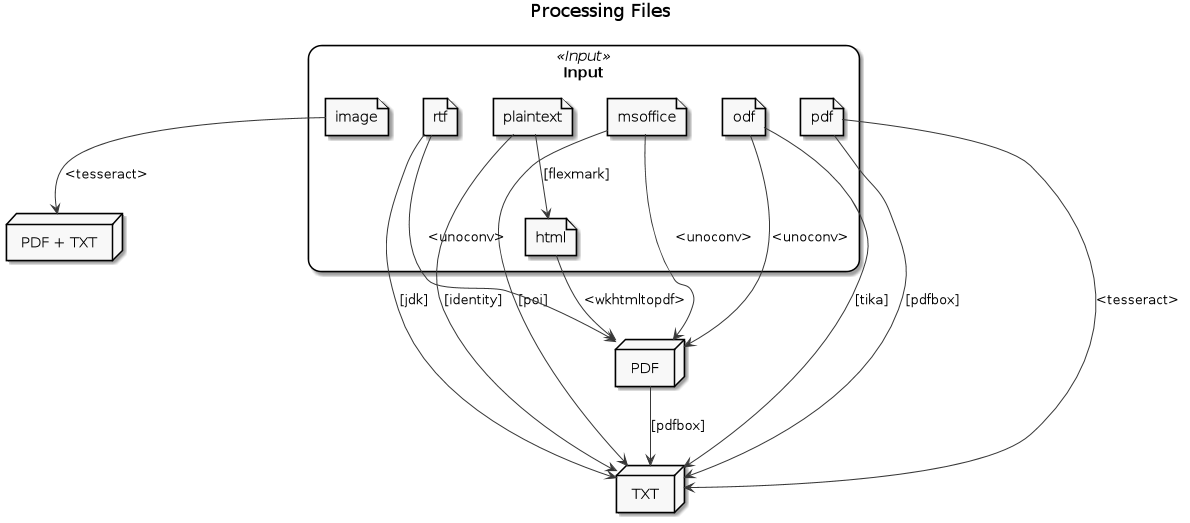
Conversion🔗
- Office documents (
doc,docx,xls,xlsx,odt,ods): unoconv (see ADR 9) - HTML (
html): wkhtmltopdf (see ADR 7) - Text/Markdown (
txt,md): Java-Lib flexmark + wkhtmltopdf - Images (
jpg,png,tif): Tesseract (see ADR 10)
Text Extraction🔗
- Office documents (
doc,docx,xls,xlsx): Apache Poi - Office documends (
odt,ods): Apache Tika (including the sources) - HTML: not supported, extract text from converted PDF
- Images (
jpg,png,tif): Tesseract - Text/Markdown: n.a.
- PDF: Apache PDFBox or Tesseract